Just a brief intro before I crack on. The last post was a bit theoretical and long and this is largely the same but probably more complicated, longer and certainly more difficult to explain. Before you read this ridiculously long post (it should be three or four different posts to be honest), a word of warning, there are more questions than answers – I’m just reading interesting stuff and testing it out. Don’t be hating.
Diffusion
In this post, I want to explore how time affects how a new idea or product is spread within a network and whether it has any actual practical uses for PR professionals. The general consensus is to use the term ‘innovation’ (for the new thing, idea, product or tool – if you are Zengestrom) and ‘adopt’. For those who read the last post, Markov centrality is about how quickly a message spreads through a network. The idea of adding a time dimension to network analysis is further explored by ‘diffusion’ which is “the process by which an innovation is communicated through certain channels over time among the members of a social system” (thanks Wikipedia). You’ve probably heard about Diffusion of Innovations, which explores adoption and much more in detail.
Diffusion works on two main assumptions. Firstly, that social relations is one of the most important channels for contagion and persuasion. Known as social contagion it implies that when you connect to people they also influence you. The assumption that social ties are important is because with an innovation, there is thought to be a risk associated with it because it is new and therefore an unknown quantity. Depending on the situation, family members, friends, colleagues will all exert different levels of influence and the individual will have different thresholds for adopting an innovation depending on what it is.
We’re nowt but sheep
Secondly, the more a person is exposed to an idea, the more likely they are to adopt it – think about all your friends who have purchased an iPhone based on the amount of nagging from iPhone users. This in turn, results in a self-perpetuating effect where the idea gets even more exposure and thus more adopters. An example of this would be the web, where popular websites continue to attract more links than less popular ones. Often refered to as preferential attachment, it is a case of the rich getting richer. In the PR industry a blogger starting his blog will probably include popular blogs such as Stuart‘s or Richard Edelman‘s blogs (both of which were created before I was born) on their blog rolls because they have heard about it from their peers. (It is also worth reading about information cascades for further evidence that we rarely make a decision on our own)
Social pressure also plays a part during the adoption process, especially if the innovation becomes popular or cool. This could be due to peer pressure and overlaps with the idea of social currency – where people do stuff to talk about it – such as buying the latest CDs or in my case, reading The Sun every morning the week before I go see my friends in Bradford. Using the example above, the new blogger may want to be seen to be reading Stuart’s blog because it’s what everyone else is reading and it also gives the blogger something to talk about/share when he meets like minded people at the various networking dos.
The pressure to adopt an idea might also be a practical one. According to Metcalfe’s law “the value of a telecommunications network is proportional to the square of the number of connected users of the system (n squared)”. Without paying too much attention to the maths (n squared should be seen as a generalisation rather than an exact formula to work out ‘usefulness and that’), you can see that during the 90’s, as more people adopted email systems in their communications it became increasingly difficult for others not to adopt. This effect can also lower individual thresholds for adoption, making it less risky for people to try new ideas or products. You could argue that Twitter has become less useful as ‘people’ like Megan start using the channel – I’ve certainly found it less useful for information since I started following more people. However, saying that, if more of my mates from Bradford starting using it, that would change and Twitter could become useful for finding out who has just had another kid, who’s been in jail, who’s managed to use a computer for something other than porn, etc.
Super susceptible vs. Super influencers
By understanding how the diffusion process works, one of the things we can do is identify groups of people who are more suseptible to persuasion and target them instead of the traditional “super influencers”.
In a directed network, nodes with more inbound links are the ones more likely to be ‘infected’. The ‘exposure’ of a node may result in the person simply having more chance of hearing about the product or could lead to more intense social pressure to conform. (I’m ignoring for this post the idea that each person has different thresholds when adopting an innovation, and the type of innovations itself). In a real world setting, it you were looking for a prominent tech blogger, the bloggers who are more likely to have their head turned are those that also subscribe to a large number of relevant blogs. Note the use of the term ‘relevant’ – as in relevant to the network you are targeting. If the blogger reads a large number of blogs that are not relevant to technology, for example, then they are less likely to conform because they are likely to have more influences. In an extreme case scenario, Apple releases an update for its iPhone and lets the users of various Mac forums know how amazing it is. Members of all the forums will be bombarded with positive messages and those that subscribe to a large number of these forums and little else will have very little evidence to distrust Apple’s claims that the new iPhone makes you 30 per cent more interesting to other iPhone users (to everyone else you are 70 per cent duller and geekier – it’s a made up fact that since Mat got an iPhone, 80 per cent of our conversations is spent talking about apps).
This is also linked to the strength of weak ties concept I mentioned in my last post. The people who have more ‘weak’ ties – i.e. peripheral to a network – are likely to have more information at their disposal (one of the reasons the UK PR social media scene often feels like an annoying echo chamber) and therefore less likely to conform (although conversely – and I know I’m contradicting myself here slightly, they are more likely to be early adopters of new innovations). Again, using the example above, those that read a more diverse range of forums, blogs, etc are more likely to be informed of flaws and/or alternatives to the latest iPhone update. What I’m saying is that those with many weak ties are less likely to conform to norms and more likely to try new ideas, products.
Using tools such as Pajek, we could find whole groups of people who will be more likely to adopt the innovation. For example, you could work out how centralised (connected) a network is – a network with more connections means that messages will spread more effectively. If it is less connected and full of bottlenecks (often called cut vertices and bridges – nodes and lines which when removed disconnect a network completely) then the messages will take longer to spread if at all.

Above is a quick sociograph of the PR comms industry. Using Netdraw (software which let’s you analyse networks), I’ve resized the nodes so that the more blogs they link to, the larger they are. Therefore we can see that Richard Bailey, Tom Murphy and We Are Social new boy, Simon Collister appear to be more susceptible to change. There are also two areas of interest – the one to the right of the centre appears to be a group of educational-focused blogs. Please bear in mind that this diagram was literally created in minutes, I took Brendan Cooper’s PR Index and mixed it with Jed‘s blog roll. Hardly scientific, it’s probably far from accurate and what’s to say that Simon is actually still reading blogs? I just wanted to illustrate what I meant and just realised that this blog post was well text heavy.
*Minor update – I’m getting confused between new innovations and adopting ideas here. People on peripheral of network (strength of weak ties) are more likely to adopt new ideas/products, people who have a lot of influencers are more likely to conform. At least I think that’s what I mean…
What do you do once you have identified these areas of high susceptibility? I think it would help in a campaign where we needed purely numbers – i.e. we need X amount of coverage (which is still often the case in PR). We would seed the information in positions with a high centrality (Markov or otherwise – though the recommendation from the brainy people seems to be nodes with high betweeness centrality) so that the message would spread to many people. By analysing the network and working out how susceptible it is to change, we can alter our tactics accordingly. For example, memes would spread much more effectively in a connected network such as the PR blogging network in comparison to a network of mid-level accountants – who, if you were trying to reach, you might use one to one meetings.
It would also help when setting goals for clients. Blogger outreach programmes are still an unknown quality – some work, others don’t – it’s due to the individuality of each blogger (and often your relationship with them) as to whether it is a success or not. The traditional media is much more predictable and established. Although you are essentially still selling your story to an individual when pitching to traditional media, ground rules have been set and they are much more consistent with what they are writing about. However, by identifying areas of high susceptibility, you could get a better idea of how a campaign will spread in a network.
Critical mass
Now I’ve hopefully established that what I’m writing does have some foundation in truth, let’s look at how it could be useful.
There’s one aspect of diffusion, which I’ve found particularly interesting and hopefully relates to our day-to-day PR trudge. During some instances of adoption, something called Critical Mass occurs, which is the point where there are a minimum number of adopters needed to sustain the process. It’s a tipping point (notice the lack of capitals – I’m not referring to Gladwell’s often criticised theories, I’m using it as a general term), when the innovation has enough momentum for it to reach the whole network and sustain – and fuel – its own growth.
It is similar to the way bacteria develops – either it does not develop quickly enough and anti-bodies wipe them out, or it grows quickly enough that it multiplies and overwhelms the body’s defence.
If networks are critical to adoption, there are a couple of rules of thumb. Bear with me here. When the idea has been adopted by between 10-20 per cent of the people who will eventually adopt – (it is no surprise to find that innovators and early adopters/opinion leaders represent 16 per cent of consumers and falls nicely in there) the acceleration of adoption rate decreases, although the adoption rate still increases. This is known as the first second order inflection point. Basically, people are still adopting the innovation but not as quickly. At this point, social cognition takes over the diffusion process and adoption reaches its critical mass – it has reached the point where enough people have adopted the idea that it self perpetuates (because of the some of the points highlighted earlier – social pressure, exposure and preferential attachment, etc), fueling its own growth. Random activity of unrelated events becomes seemingly more predictable as a kind of self-organisation takes over.
This is Roger’s innovation adoption curve shows what the diffusion process looks like:
*Stolen from http://www.mitsue.co.jp/english/case/concept/img/02/fig1.gif
The ‘S’ shaped curve being the cumulative rate of adoption (or diffusion curve) and the bell curve being the number of new adopters. So in an ideal rate of diffusion, the point of critical mass (which those Japanese fellas have labeled as the diffusion rate line on this graph) is around the point of the first inflexion in the ‘S’ shaped curve and is about 10-20 per cent the total number of adopters. Theoretically then, at the first inflexion we can assume that the total amount of eventual adopters will be between five and ten times the number at that point. As with triangles and the distance/speed/time diagram in physics, if we knew the eventual number of people who will be adopting the idea (i.e. the client has set a goal of X number of people), we can predict what the critical mass should be and plan our comms activities accordingly. Am I making sense?
Facebook Ads and critical mass
Let me show you a real life example. I recently created a Facebook fan page for a client. We had no budget for Facebook ads and much of our traffic came from Twitter. I’ve tried to take into account the number of fans who joined the group as a result of an email from me or from Twitter (I used cli.gs to track as much as I could) but it’s far from perfect.
The graph looks like this:

And the numbers were as such:

*Adoption rate is the number or percentage of new adopters at a particular moment in time; and the Acceleration is how quickly the innovation is being adopted.
At Time 3 the total number of fans is 29. Therefore, we could estimate that the number of eventual fans to be between 145 and 290 (the mean of which is 217.5). For this particular campaign, we had no targets set for the number of fans (and who’s to say that a fan page needs X amount of people to be successful?), but sometimes the client wants a certain number of fans for it to be deemed a success. So for example, if the client wants at least 1000 fans, at that point of critical mass we can see that there is very little chance we’d ever get close to reaching that number.
Creating momentum
The question (and solution?) is, could we then artificially create the required number of people through above and below the line activities to create the momentum needed to reach that goal? In the case of the Facebook Fan page we could create an ad campaign or target relevant groups promoting the fan page, inflating the numbers so that at the first point of inflexion, the number of fans is closer to 200 (and so the final number of fans is around 1000 at least).
Could we do the same during a blogger outreach programme? If the figures were not quite sufficient, we could spend more time targeting more bloggers in the network?
What we are essentially trying to create here is a ‘viral’ effect. I know viral, word of mouth, etc is an outcome not a strategy/tactic – but it’s not some mythical, impossible dream – there are some things we can do to try and achieve that effect. Mat has previously written a post about creating the appearance of acceleration on his blog, which talks about how evangelists do exactly what I’m proposing we do.
Caveats
Here’s a few things to consider and why I may have just waited an hour of your life. Critical mass theoretically exists only when the network is the key driver in adoption – i.e. the innovation spreads organically via social ties and word of mouth. To this end, it could be argued that if you artificially created the appearance of acceleration using above the line activities then you would not be relying solely on networks to promote your Facebook page – your fans would be isolated, unrelated groups of individuals who exist in different networks. However, the great thing about Facebook Fan pages (and why I’m a bigger advocate of them over Facebook groups for clients) is that you can use Facebook Ads to target audiences based on specific demographic and interests. Want to target a married male, aged 23 from London who has an interest in 3D animation? Facebook Ads lets you do that. While two people who have an interest in say, Manchester United may not be directly connected, they will exist within the same network. Studies have shown that people tend to associate with others who have a common interest. Known as Homophily, it is often expressed as the adage: Birds of a feather flock together. Therefore by targeting a specific demographic, you are in effect, targeting whole networks. Have a look at this post, to see many of the decisions we make are governed by our networks.
On the other hand, there is no actual proof that critical mass even exists. Even in examples where the point of critical mass is around 16 per cent of the overall population, it only implies that critical mass exists. There are also many that arguments as to which point in the adoption process critical mass actually takes place (some argue that it is when 50 per cent of all the population have adopted, while others believe that it is the period with the highest adoption rate).
Diffusion, also works on the assumption that innovators and early adopters influence the early majority. While I don’t doubt this, their influence may not be as profound as many believe. The idea that a chasm exists between this group and the early majority has been explored in Crossing the Chasm – a book I haven’t read so do not want to write about it too much. But basically, the network effect is not as simple as my fancy diagrams would have you believe.
Any way food for for thought and that and I hope you try some of this stuff out to prove me wrong. I’ve no idea why I spent so much time writing the second half of this post knowing that much cleverer people than me argue whether it is in fact bollocks.
Good night!


 ) is equal or greater than i’s threshold (
) is equal or greater than i’s threshold ( ). Conversely there is no chance of i adopting if the number of people is less than its threshold.
). Conversely there is no chance of i adopting if the number of people is less than its threshold.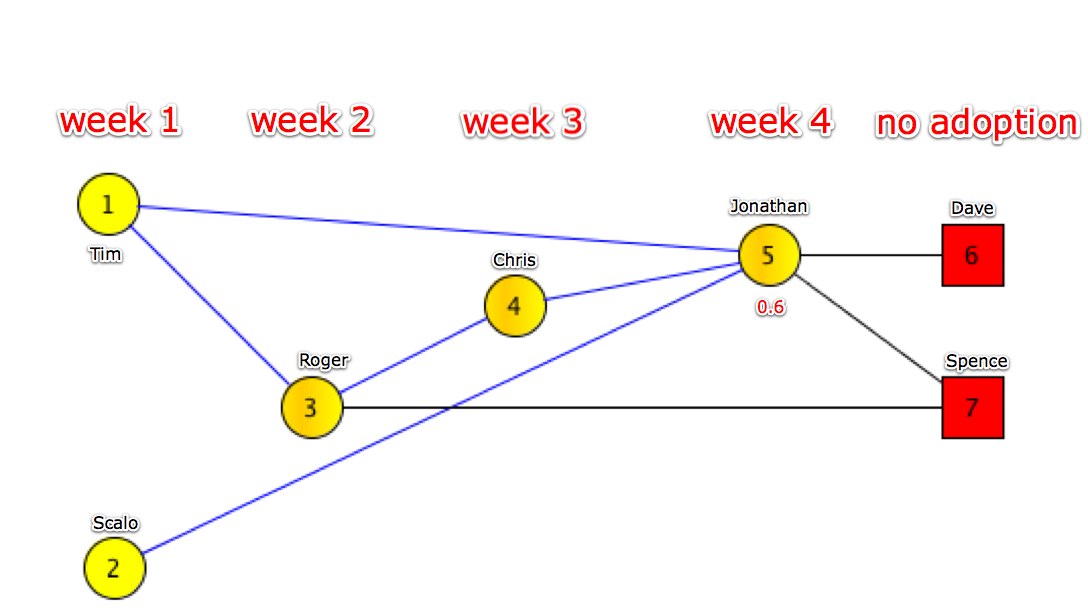
")













{kind=link}
{kind=link}
{kind=link}